AI技术-大模型工程技术汇总
本文记录一下最近一个月学习的大模型相关的技术知识点,为拥抱AI浪潮做些技术储备。
`大模型术语相关
参数规模
GPT 3.5 千亿级别
GPT4 1.8W亿级别
国内一般都是十亿或百亿级别
ChatGLM2_2K_6B
BAICHUAN_4K_13B
淘宝星辰_4K_13B
TOKEN长度
Token是指被LLM处理的离散的数据单元,可能是一个单词、也可能是一个字符,这个是由上下文决定的。
TOKEN数量是指 输入和输出加起来的长度之和
TOKEN数量,决定了 prompt和输出的长度,同样会影响推理的速度,prompt越长,推理时间越长。
TOKEN的数量为什么会有上限,是有什么限制么?
各个版本的token数量限制
GPT3.5-turbo 是4096个token
GPT3.5_16K
GPT4_Turbo_128K
大模型工程落地相关
prompt
零样本
少样本:通过举例
思维链
角色、限制条件
LangChain
软件开发框架,帮助开发者快速且灵活地调用大模型,也封装了许多常见的chain,可以被业务快速使用。
Semantic-Kernel
微软的一个工程框架,也可以实现langchain的基本功能,不过更适用于多agent的框架。
RAG(检索增强生成)
是一种结合外部知识库来增强LLM生成能力的总称。
向量数据库
Embedding:将现实世界中的物质向量化到高维空间,向量距离通常代表了自然语言的语义相似度。
召回:向量召回、搜索召回
Agent
简单来说是具有某个功能的原子能力,可以被大模型调用到。
多Agent
多个agent协同完成一个目标,比如metaGPT
大模型训练相关
预训练
通过大量的数据训练出来的模型
推理
模型根据已有的经验,对用户的输入进行预测。
微调
预训练好的模型在特定的任务上进行微调,使用有标签的小规模数据集
训练基础设施
pytorch 是一种深度学习框架,用来训练大模型的,transformer是一种模型机制。
计算资源
CPU:传统的CPU芯片,重逻辑,轻计算。
GPU:类众核CPU,重计算,轻逻辑。A100 H100 4096等,代表了不同的算力,常见的衡量指标有Flops
TPU :谷歌出的类似于GPU的芯片
LangChain框架
1. LangChain解决什么问题
LangChain是基于LLM之上的,在应用层和底层LLM之前的一个很好的编程框架,如果把LLM比喻为各种类型的数据库、中间件等这些基础设施,应用层是各种业务逻辑的组合之外,那么LangChain就负责桥接与业务层和底层LLM模型,让开发者可以快速地实现对接各种底层模型和快速实现业务逻辑的软件开发框架。
那么LangChain是如何做到的呢?试想一下,现在底层有一个大模型的推理能力,除了在对话框手动输入跟他聊天之外。如何用计算机方式跟它互动呢?如果把一次LLM调用当作一个原子能力,如何编排这些原子能力来解决一些业务需求呢?Langchain就是来解决这个事情的。
2. LangChain的几个核心概念
格式化数据(I/O)
Retriver
检索是为了解决大模型打通用户的本身数据,做一些面向业务属性的东西。这里的检索并非传统的关系型数据库,更多的是与大模型的本身逻辑相似的,比如向量数据库。
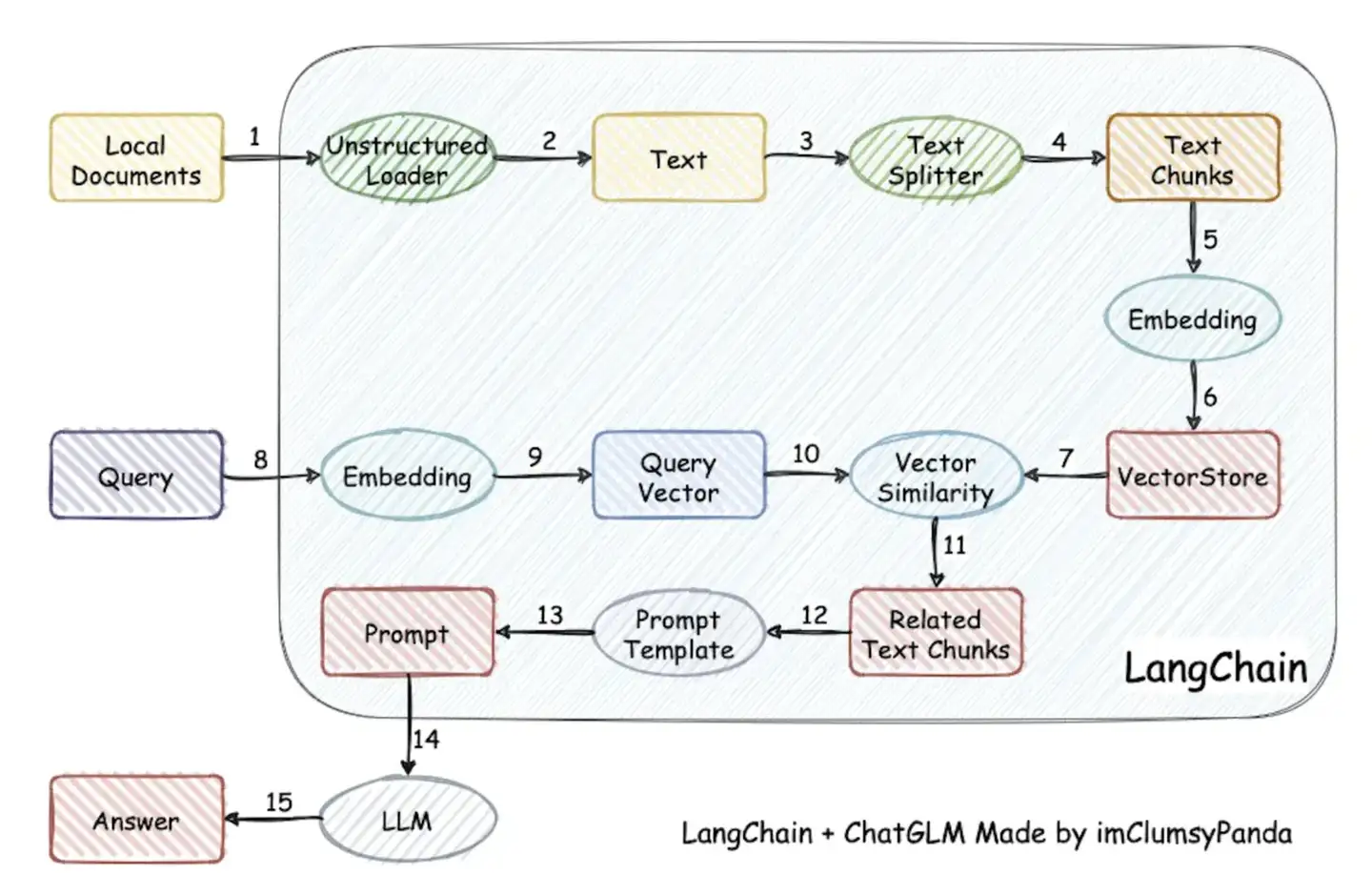
一个经典的结合LLM和外部用户的文档进行智能答疑的场景
文档->分词->embedding->向量数据库
query->向量数据库查询->TOP N->上下文+ 用户提问 + prompt -> LLM -> 返回结果
一个经典的图如下:
添加图片注释,不超过 140 字(可选)
关键技术:文档如何拆分、embedding过程、 TOPN 向量距离的选择
embedding技术选型
embedding是将现实中的物体通过向量化的方法转化为高维向量,可被机器学习模型所识别。他是一种映射,同时也保证了能清晰地表达现实物体的特征。基于此,可以进行一些归类分析、回归分析等。
现在市面上常见的embedding方法有通义千问的embedding等方法。
向量数据库
向量数据库底层存储的是一堆向量,它提供了根据向量相似度进行查询的能力,一般情况下,向量相似度代表了现实世界中物体的相似度。比如”我的名字是小明“ 和“我叫小明”这两句话所代表的含义几乎是相同的,那么在embedding之后,基于向量数据库进行查询的时候,它们俩的相似度就会很近。
Chain
各种类型的chain,chain代表了各种业务类型的组合,类似于工作流的编排。
Memory
LLM本身提供了记忆的能力,同时提供了接口,开发者可以将历史的对话记录传入给LLM。LangChain需要使用外部存储保存这些历史的会话和记忆。可以使用数据库、缓存等进行保存。
Agent
重点是代理工具
代理工具可以让应用程序基于大模型的推理能力,然后进行代理工具或代理服务的调用。因为LLM是没有“联网”的能力的,如果想解决特定的应用场景,代理工具是个完美的选择。
代理工具通常包含三个方面: 用户输入、prompt编排LLM思考与路由代理的过程、背后的代理服务。其中难点可能就在于prompt设计了。通常的“套路”是这样的:
ReAct 模型
输入:用户的问题
思考过程:如果是情况1(这个是需要LLM进行意图识别进行思考的),那么推理和提取出一些关键参数,调用agent1,如果是情况2,那么推理和提取出一些关键参数,调用agent2
Act:调用agent1对应一个JSON格式化的输入,调用function1,返回结果。
观察:观察调用后的结果,再结合推理的能力,再进行循环思考。
Semantic Kernel 框架
功能基本与langchain功能相同,在应用层和LLM层中间实现了一个编程框架。框架可以灵活、快速地对接LLM模型,帮助开发者可以快速落地AI业务。
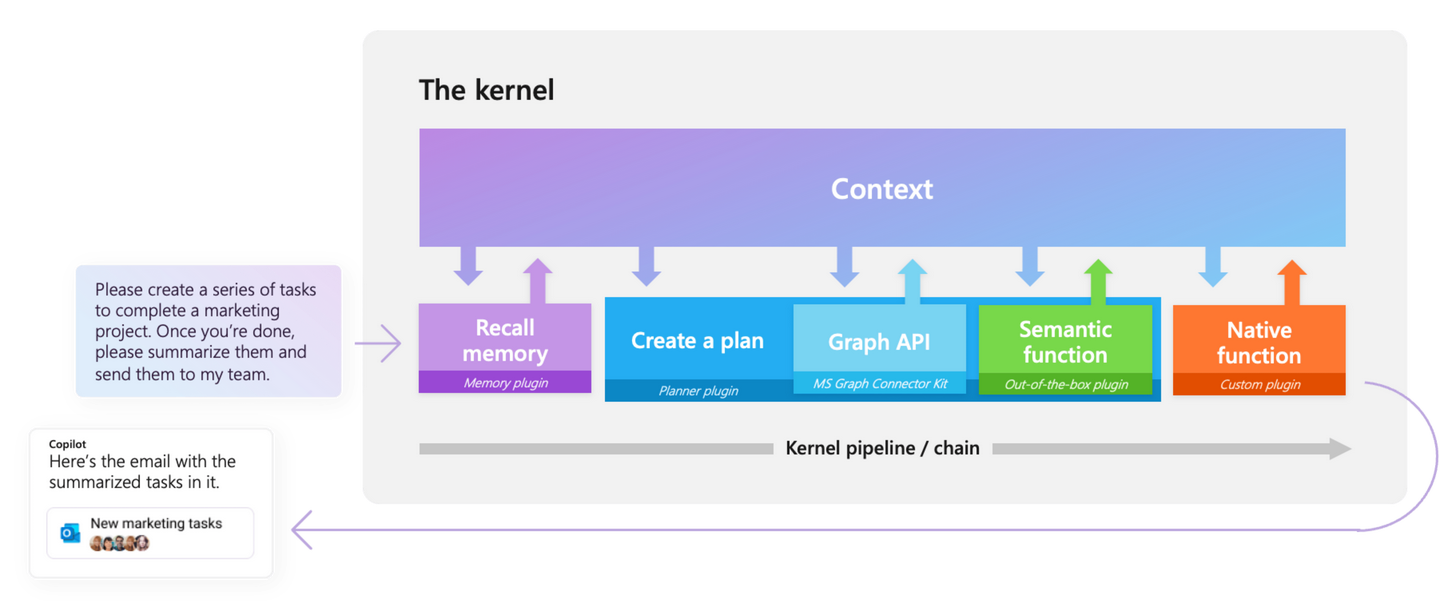
1. Kernel
添加图片注释,不超过 140 字(可选)
kernel都包含哪些?
上下文
主要包含三部分:
ContextVariables,用来存储LLM中间返回结果,是一个全局的运行时变量存储,方便各agent或各skfunction进行引用。
SemanticTextMemory:管理内存,这里可以类比向量化数据库。
ReadOnlySkillCollection 管理注册的skill与function这些元数据。
SkFunction
SKFunction是一个具体功能的描述,包含 description、prompt、以及大模型相关的参数配置项,比如温度值等
skill是一组function功能的集合
Planner
对解决一个复杂场景问题,结合一堆function,设定一个goal,给出LLM思考逻辑,生成具体执行计划,然后调用skfunction
PlugIn
与真实世界进行对接,让LLM有“联网”的能力,可以是API接口,也可以是向量数据库、也可以是本地函数等等。
2. Demo实践
代码:官网上下载的JAVA版本
基础的问答
- kernel构建
1 | |
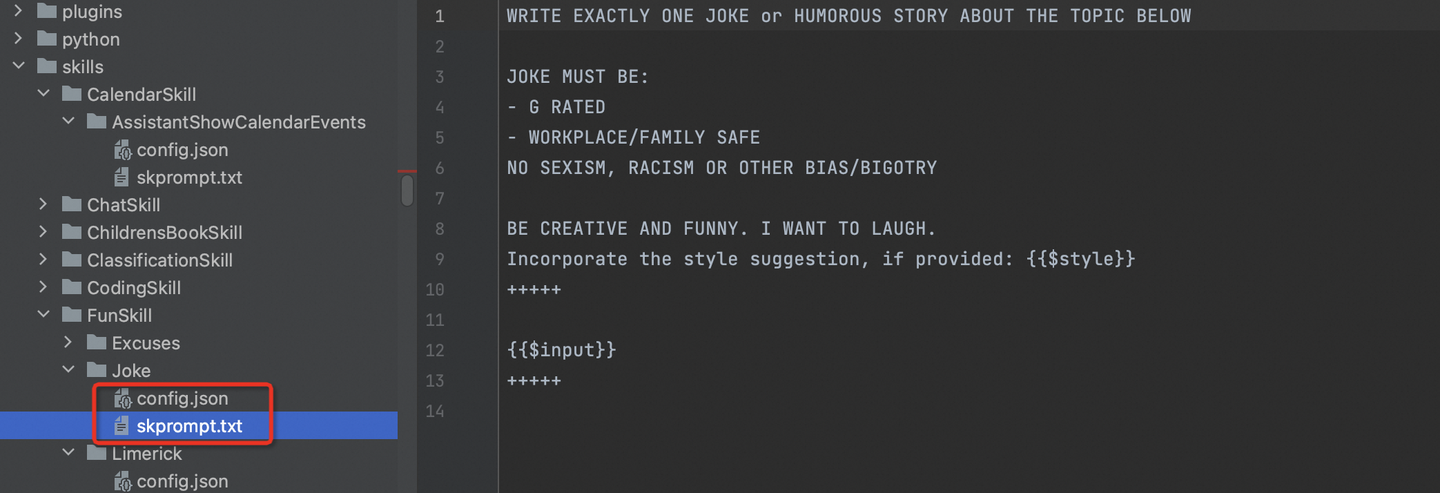
- skill和function编写,提示词和gpt参数设置
添加图片注释,不超过 140 字(可选)
- 引入skill与function
1 | |
多Agent执行完成一个目标
以Example_PlanWithNativeFunctions 为例子,这个例子接收用户指令:给Steven发一封邮件,并且有限使用Steven的备注名,具体的函数有:Emailer 邮件功能 、寻找人名的备注名称、以及字符串替换的功能
- Plan通用思考提示词(SK系统)
1 | |
- 生成执行计划–XML文件(SK系统)
1 | |
- 定义每个SKFunction的功能以及接收的输入参数(用户自定义)
1 | |
- 使用Plan进行调用
1 | |
3. 思考
与LangChain的对比
| LangChain | Semantic Kernel | |
|---|---|---|
| 开发组织 | 社区 | 微软 |
| 设计理念 | Model I/O 、 Retriver、Chain、Memory | Kernel、SKFunction、ContextVar、Plan、Plugin |
| 支持语言 | python | python/c#/java,主推python与c# |
| 社区活跃 | 活跃,功能迭代很快 | 比LangChain慢 |
| 生态集成 | 集成了各种Model I/O | 生态集成没有LangChain高 |
| 记忆能力 | 支持 | 支持 |
| 支持多LLM切换 | 支持 | 支持 |
| RAG支持 | 支持Retriver | 支持Memory |
| Agent支持 | 支持 | 支持 |
| 多Agent支持 | 支持LangGraph | 支持Planner |
4. 其他思考
Semantic kernel 的function与planner 抽象的比较好,可以通过planner来实现复杂场景的企业级AI应用。LangChain更适合快速落地一个AI应用,已经沉淀了各种Chain,拿来即用。同时LangChain已经推出LangGraph了,已经在实现类似Planner的功能。
Embeding技术
1. 介绍
将现实世界中的信息映射到低维的向量空间上。机器学习训练中的一个环节,在大模型产生之前就已经有了。
2. 应用场景
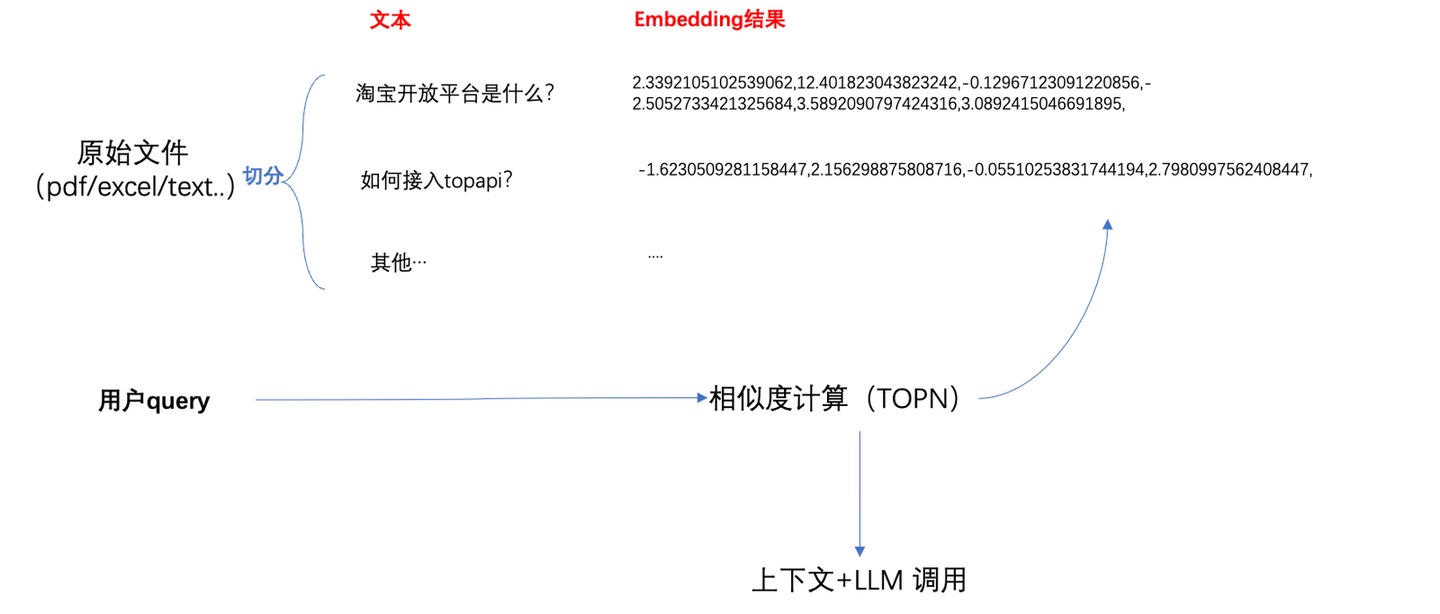
RAG向量召回场景
添加图片注释,不超过 140 字(可选)
RAG使用中的场景
机器学习训练特征提取
降维、特征提取、数据压缩等
3. 如何生成向量
常用embedding技术
一般分为在线服务和离线服务
https://huggingface.co/spaces/mteb/leaderboard这个网站介绍了当前主流的一些embedding技术以及排行榜情况。
目前了解到的一些embedding技术包括:Word2Vec、通义千问embedding、text-embedding-3-small and text-embedding-3-large openAI embedding
图像embedding
一般用于图像分类、目标检测、计算机视觉等,不详细展开。
视频embedding
一般用于视频检索、视频内容理解、视频推荐等,不详细展开
4. 如何计算相似度
欧几里得距离
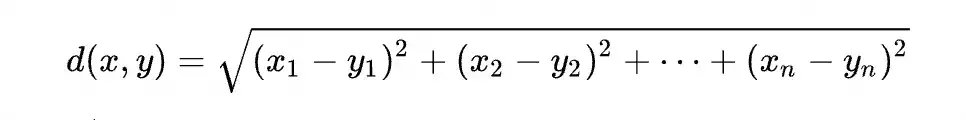
添加图片注释,不超过 140 字(可选)
余弦距离
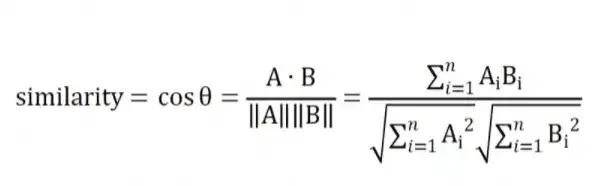
添加图片注释,不超过 140 字(可选)
曼哈顿距离
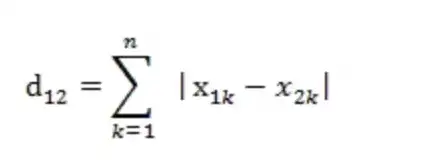
添加图片注释,不超过 140 字(可选)
5. 代码示例
文本:“你是谁”?
方法:通义千问在线embedding
结果:

添加图片注释,不超过 140 字(可选)
1500+维度的空间向量
6. 思考
1.Embedding作为召回策略中的一种,不同的embedding模型可能会对召回产生不同的影响,最好与LLM本身采用的embedding技术保持一致。
2.向量召回只是RAG召回策略中的一种,还包括搜索召回等其他方法。
微调技术
1. 背景
最近尝试了RAG技术实现了基于LLM上的智能答疑,也尝试了工作流的生成,发现效果严重依赖于大模型的能力,同时好的大模型成本又比较高,每次调用需要从知识库中召回大量的文档,从而消耗大量的token,所以在思考是否可以尝试通过将这些文档微调到大模型上。同时在思考是否也不需要超大参数的模型,是否可以基于小模型和业务数据来微调出自己的业务垂直模型。
同时我发现微调也没那么容易上手,因为这对于将来模型调试后的效果还是挺重要的,同时,理解一点基础的原理还是有必要的,仅仅是参照网上的教程一步步执行命令行,不晓得其中的原理,很容易一头雾水。
2. 什么是预训练模型
其实在之前已经有预训练模型的一些概念了。比如CNN、RNN等。其大概原理是每次训练,与目标值计算得出损失值,反向传播驱动模型迭代更新,使得下一代迭代更精确。
CNN:适合于图像领域
RNN:适合于自然语言NLP
Transformer模型:基于RNN之上增加了并行处理和注意力机制的特性。
3. 什么是微调
在已经训练好的大模型基础上,使用特定的数据集进行进一步的训练,以使模型适应特定任务或领域。有一个例子解释的挺好:小明刚刚学会了开车,那么他已经掌握了一些基础的开车技巧,比如起步、踩油门、转弯、换挡、靠边停车等一些基础技能。在微调的过程中,小明要适应在湿滑的泥地、大雾天气、山路陡坡、雨雪天等场景下开车,以适应新的场地要求。
4. 什么情况下微调
训练自己垂直领域的大模型,以适应自己特定领域的任务, 但是数据规模小,同时计算资源又稀缺。
5. 为什么会有不同的微调方法?
假设我们把训练过程简单定义为:Y(真实结果)=W(模型)*X(输入)
Y=[y1,y2,y3,y4,y5…yn] X=[x1,x,2,x3,…xm],Y和X是Embeding之后的矩阵向量,那么最后优化的就是这个W。
那么对于新的数据集X和Y,如何优化W,一种办法是W中加入一些低纬度的矩阵权重,另一种办法是X做一些演变,根据数据集去优化W。以下就是几种方法的基本原理。
6. 几种方法
LoRA
新权重 = 原始权重 + AB。
Y =(W*@W)*X
数学上的含义:假设 预训练模型是训练中间的神经网络,我们把最终生成的这个“神经网络” 比喻成是矩阵变换A X 矩阵变化B X 矩阵变化C ….,那么最终生成的预训练模型就是超大规模的矩阵变化集合。那么微调就是在这个超大规模的矩阵变化中,加入一些低纬度的矩阵变化,通过训练给入的小规模入参,优化这些低纬度的矩阵变化过程,最终来适应这个特定领域的“逻辑”
Prompt Tuning
Y = WX`
就是在输入端加入一些提示词,以增大生成期望结果的概率。简单来说:给定预训练模型的参数,然后在模型的输入端添加可学习的”prompt”(提示)进行调整
7. 部署教程
参考资料
https://www.heywhale.com/mw/project/6436d82948f7da1fee2be59e
准备工作: 数据集、微调训练方法 P-tuning v2
基础环境:GPU、pyTorch、模型文件、数据集文件
验证:使用Langchain进行简单测试验证。