AI技术-LangChain原理解析
最新越发觉得AI的发展,对未来是一场革命,LangChain已经在工程设计上有了最佳实践,类似于AI时代的编程模型或编程框架,有点Spring框架的意思。之前在LangChain上也有些最佳实践,所以在这里分享记录下。
`LangChain属于哪一层
LangChain是基于LLM之上的,在应用层和底层LLM之前的一个很好的编程框架,如果把LLM比喻为各种类型的数据库、中间件等这些基础设施,应用层是各种业务逻辑的组合之外,那么LangChain就负责桥接与业务层和底层LLM模型,让开发者可以快速地实现对接各种底层模型和快速实现业务逻辑的软件开发框架。
那么LangChain是如何做到的呢?试想一下,现在底层有一个大模型的推理能力,除了在对话框手动输入跟他聊天之外。如何用计算机方式跟它互动呢?如果把一次LLM调用当作一个原子能力,如何编排这些原子能力来解决一些业务需求呢?Langchain就是来解决这个事情的。
LangChain的几个核心概念
格式化数据(I/O)
Retriver
检索是为了解决大模型打通用户的本身数据,做一些面向业务属性的东西。这里的检索并非传统的关系型数据库,更多的是与大模型的本身逻辑相似的,比如向量数据库。
一个经典的结合LLM和外部用户的文档进行智能答疑的场景
文档->分词->embedding->向量数据库
query->向量数据库查询->TOP N->上下文+ 用户提问 + prompt -> LLM -> 返回结果
一个经典的图如下:
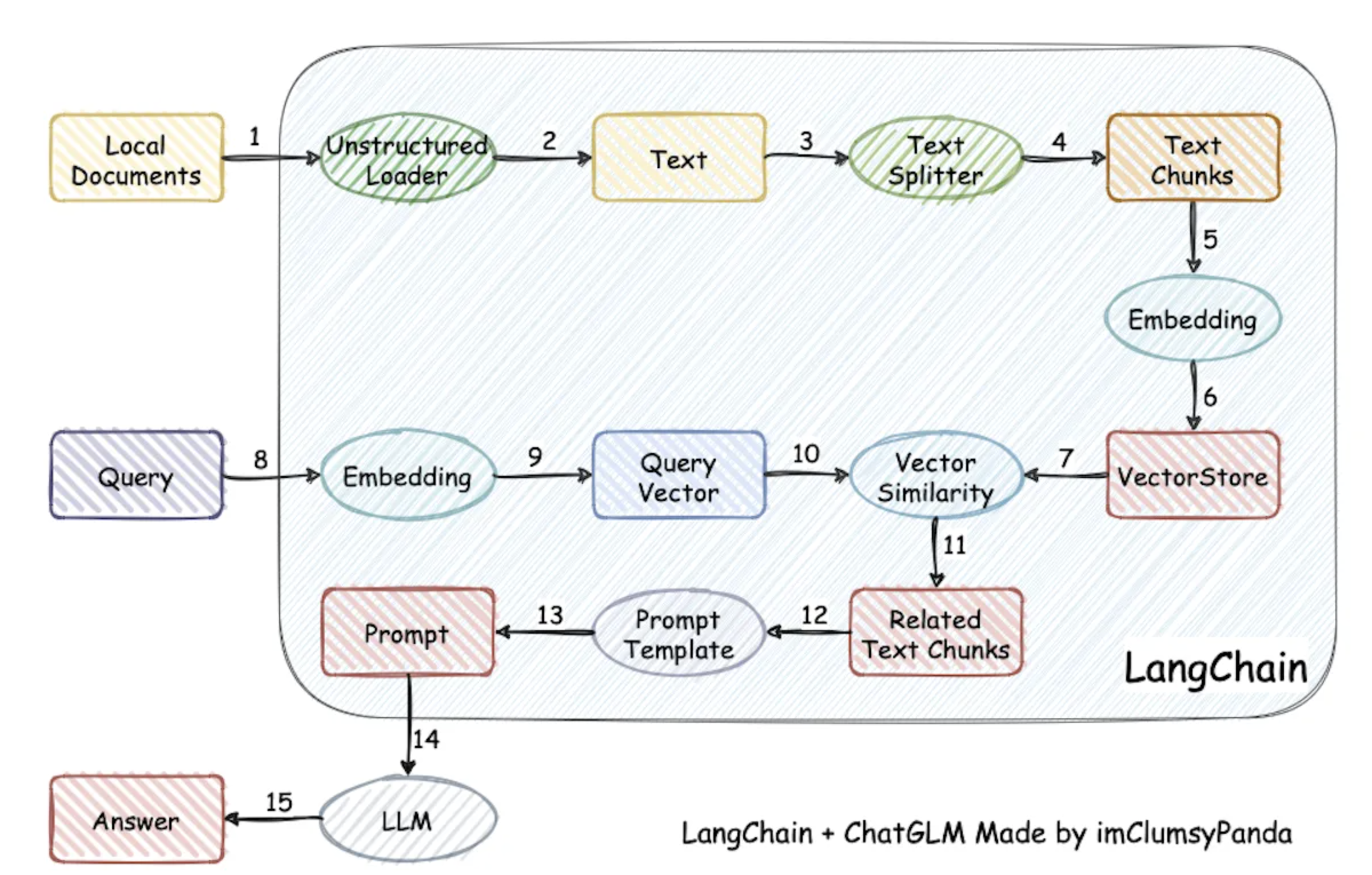
关键技术:文档如何拆分、embedding过程、 TOPN 向量距离的选择
embedding技术选型
embedding是将现实中的物体通过向量化的方法转化为高维向量,可被机器学习模型所识别。他是一种映射,同时也保证了能清晰地表达现实物体的特征。基于此,可以进行一些归类分析、回归分析等。
现在市面上常见的embedding方法有通义千问的embedding等方法。
向量数据库
向量数据库底层存储的是一堆向量,它提供了根据向量相似度进行查询的能力,一般情况下,向量相似度代表了现实世界中物体的相似度。比如”我的名字是小明“ 和“我叫小明”这两句话所代表的含义几乎是相同的,那么在embedding之后,基于向量数据库进行查询的时候,它们俩的相似度就会很近。
现在市面上常见的向量数据库有xxx
Chain
各种类型的chain,chain代表了各种业务类型的组合,类似于工作流的编排。
Memory
LLM本身提供了记忆的能力,同时提供了接口,开发者可以将历史的对话记录传入给LLM。LangChain需要使用外部存储保存这些历史的会话和记忆。可以使用数据库、缓存等进行保存。
Agent
重点是代理工具
代理工具可以让应用程序基于大模型的推理能力,然后进行代理工具或代理服务的调用。因为LLM是没有“联网”的能力的,如果想解决特定的应用场景,代理工具是个完美的选择。
代理工具通常包含三个方面: 用户输入、prompt编排LLM思考与路由代理的过程、背后的代理服务。其中难点可能就在于prompt设计了。通常的“套路”是这样的:
ReAct 模型:
输入:用户的问题
思考过程:如果是情况1(这个是需要LLM进行意图识别进行思考的),那么推理和提取出一些关键参数,调用agent1,如果是情况2,那么推理和提取出一些关键参数,调用agent2
Act:调用agent1对应一个JSON格式化的输入,调用function1,返回结果。
观察:观察调用后的结果,再结合推理的能力,再进行循环思考。
LangChain的在实际场景中的实践
智能问答
Embedding 是将FAQ的知识库
prompt+embedding+ 向量数据库+agent